
티스토리 뷰
데이터셋의 구분과 교차검증 알고리즘에 대해 알아보고, Iris 데이터셋을 활용하여 이를 구현해본다.
Train/Test/Validation Dataset
Train Data : 모델 학습하는 과정에서 파라미터 값을 산축하는 과정에서 사용하는 데이터
Test Data : 학습한 모델의 성능을 평가하기 위해 사용하는 데이터
Validation Data : 모델이 과적합되는지를 확인하기 위해 사용하는 데이터

데이터를 나누는 이유?
모델을 일반화시키기 위한 방법으로, 과적합을 막을 수 있다.
Overfitting
ML 모델이 훈련 데이터를 지나치게 학습한 상태로, 새로운 데이터에 대한 예측이 어렵다.
훈련 데이터에 대한 성능은 높지만, 일반화된 데이터에 대해 성능이 떨어진다.
Overfitting 원인
모델 복잡도 : 모델이 복잡하면 훈련 데이터의 노이즈까지 학습이 가능하여 새로운 데이터에 대한 예측력이 떨어진다.
훈련 데이터 부족 : 훈련 데이터가 부족하여 데이터의 일반적인 패턴보다 특정 샘플에 대해 과도하게 학습이 될 수 있다.
Overfitting 해결방법
훈련 데이터 양 증가 : 훈련 데이터 양을 증가시켜 데이터의 일반적인 패턴을 학습하도록 한다.
정규화(Normalization) : 모델의 복잡도를 제한하여 과적합을 막는다.
교차 검증(Cross-validation) : 데이터를 여러 부분 나누어, 일부를 검증에 사용하여 모델의 일반화를 개선한다.
드롭아웃(Dropout) : 신경망 훈련 과정에서 일부 뉴런을 임의로 비활성화시킨다.
Underfitting
ML 모델이 훈련 데이터에 있는 패턴을 충분히 학습하지 못해, 새로운 데이터에 대한 예측을 수행하지 못하는 상태를 의미한다.
Underfitting 원인
모델 복잡도 부족 : 모델이 단순하여 데이터의 복잡한 구조를 학습할 수 없다.
훈련 데이터 부족 : 충분한 양의 훈련 데이터가 없어 모델이 데이터의 다양성을 학습하기 어렵다.
Underfitting 해결방법
모델 복잡도 증가 : 복잡한 모델을 사용하거나, 모델에 파라미터를 추가해 데이터의 복잡성을 증가시킨다.
데이터 양 증가 : 데이터 증강 기법(Sampling)이나 추가 데이터 수집을 진행한다.
특성 공학 : 데이터 특성 추가 및 재구성을 통해 알고리즘에 특성을 제공한다.
Cross-Validation
ML 모델의 성능을 평가하고 과적합을 피하면서 일반화 능력을 검증하기 위하기 위한 기법으로, 데이터를 여러 부분으로 나누어, 일부는 훈련에 활용하고, 다른 일부는 검증에 사용한다.
k-Fold Cross Validation
전체 훈련 데이터를 k개의 부분 집합(폴드)로 나누고, k-1개의 폴드를 훈련 데이터, 나머지 1개의 폴드를 검증 데이터로 사용하고, 이를 k번 반복하여, k개의 정확도를 평균으로 하는 교차 검증 기법이다.
장점. 모든 데이터 셋을 평가에 활용할 수 있어 overfit과 underfit을 방지할 수 있으며, 데이터의 편향을 막을 수 있다.
단점. 계산 비용이 높고, 노이즈 값이 큰 데이터들이 균일하지 않다면, 성능 평가가 제대로 이루어질 수 없다.
LOOCV(Leave-one-out Cross-validation)
데이터셋의 샘플 수만큼 폴드를 만들어, 하나의 데이터를 검증 데이터로 사용하고, 나머지를 훈련 데이터로 사용하는 교차검증 기법이다. 즉, n개의 데이터가 있을 때, n번의 교차 검증을 수행하게 된다.
장점. 모든 데이터 샘플에 대해 검증을 수행하여 랜덤성이 없으며, 편향성이 낮다.
단점. 데이터셋의 크기가 클수록 계산 비용이 매우 높고, 실용적이지 않다. 과적합되어 높은 분산을 갖는다.
Stratified K-fold
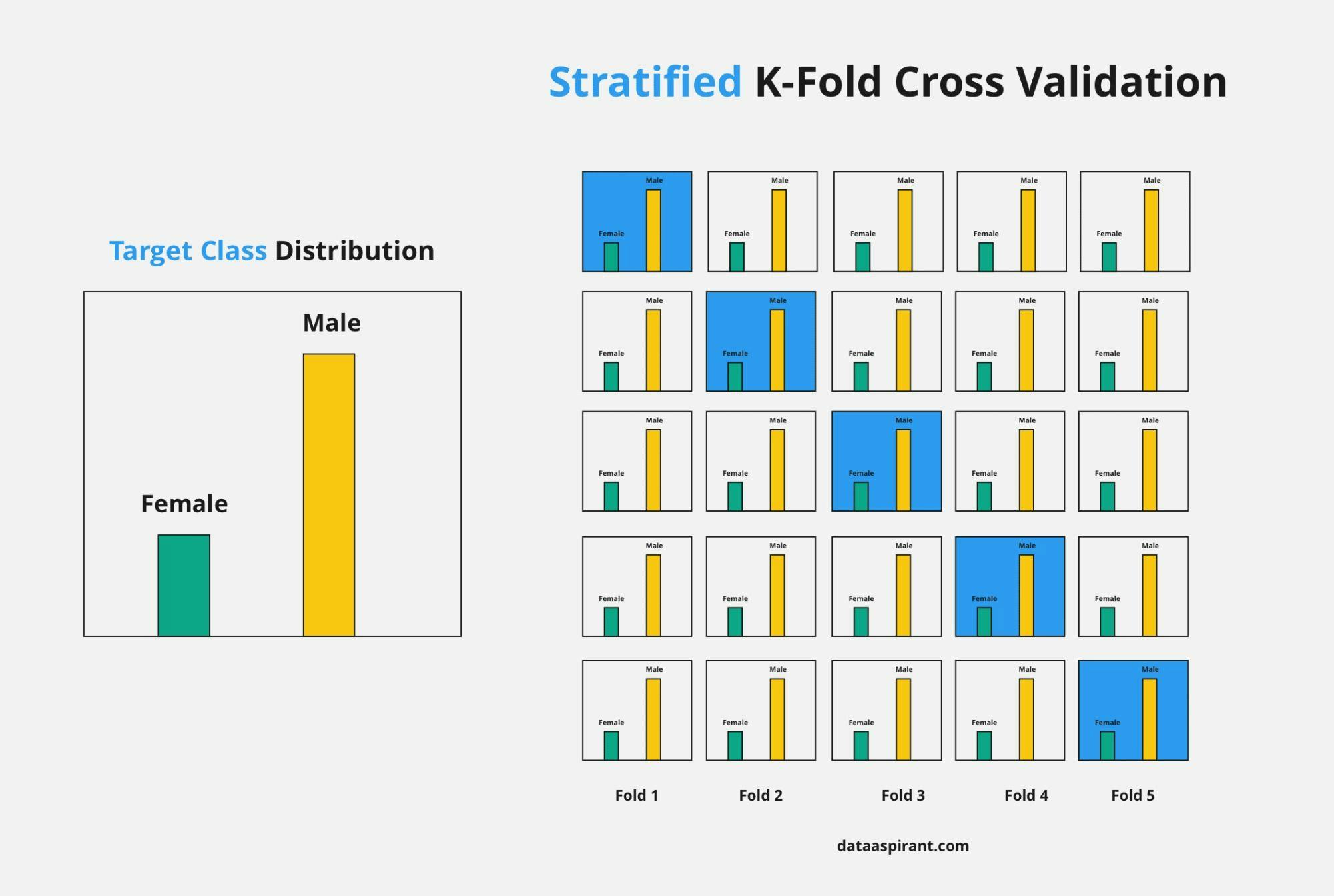
k-Fold 교차검증에서 한 단계 더 나아가, 각 폴드 내 데이터의 분포가 전체 데이터셋의 분포를 잘 반영하도록 조정하는 교차검증 기법으로, 분류 문제에서 각 클래스의 비율을 유지하여 데이터를 나눈다.
장점. 클래스 불균형 문제를 해결하여 더 정확한 성능 평가가 가능하다.
단점. 구현 과정이 k-Fold보다 복잡하다.
Nested Cross Validation
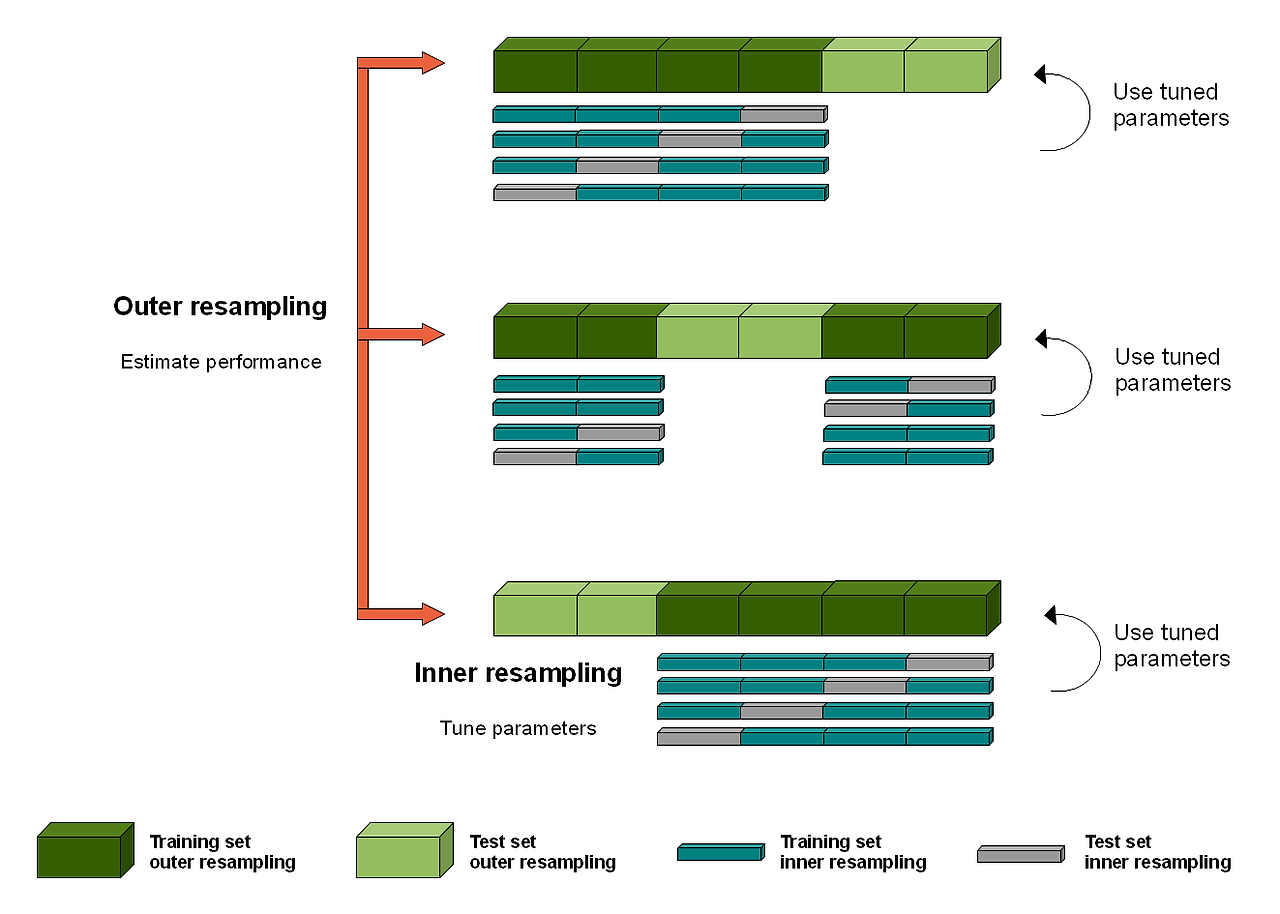
모델 선택과 하이퍼파라미터 튜닝을 위해 내부와 외부 두 개의 교차 검증 과정을 사용하는 방법으로, 외부 교차 검증은 모델 성능 평가를 위해, 내부 교차 검증은 하이퍼파라미터를 찾기 위해 사용된다.
Outer resampling : Train data와 Test data에 대한 cross validation으로, 모델의 성능 평가를 위해 진행한다.
Inner resampling : Train data와 Validation data에 대한 cross validation으로, 최적의 하이퍼파리미터를 탐색한다.
장점. 검증 및 테스트를 모두 거치기 때문에 모델 성능과 파라미터 튜닝의 편향을 최소화한다.
단점. 많은 시간과 계산 비용이 매우 많이 든다.
TimeSeriesSplit
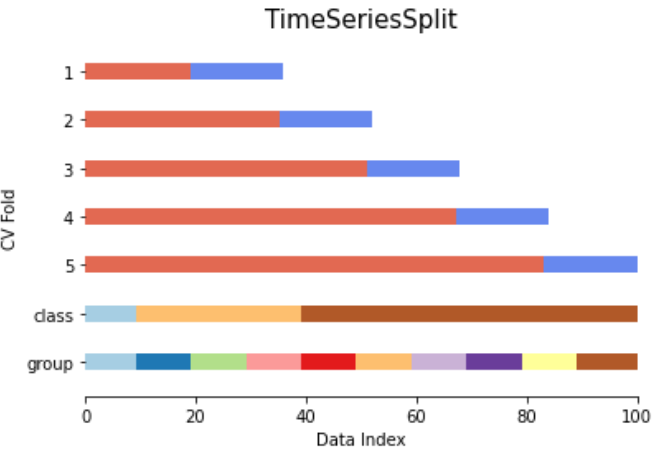
시계열 데이터에 적합한 교차 검증 방법으로, 각 폴드에서 train set(과거 시점)를 활용하여 test set(미래 시점)을 테스트하는 과정을 가진다. 시계열 특성 상 폴드가 누적되는 형태를 가지게 된다.
장점. 시계열 데이터의 시간적 특성을 반영할 수 있다.
단점. 시계열 데이터가 아닌 경우 활용도가 떨어진다.
Iris 데이터셋을 활용하여 코드 구현
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
# iris data 불러오기
iris = load_iris()
iris_data =iris.data
iris_label = iris.target
iris_df = pd.DataFrame(data=iris.data, columns = iris.feature_names)
# 데이터셋 정의
iris_df['y']= iris_label
train_test_split을 통해 데이터를 나눈다.
test_size : traindata와 testdata의 비율
random_state : random_seed와 같은 개념으로, 난수 지정 역할
#데이터 분리
from sklearn.model_selection import train_test_split
#train, test 데이터셋 분리
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size=0.3, random_state=111)
DT를 활용하여 데이터를 학습시킨다.
x_train, y_train : 학습을 위해 사용한다.
x_test, y_test : 검증을 위해 사용한다.
y_test는 ML모델을 통해 출력된 y_pred와 비교한다.
df_clf = DecisionTreeClassifier(random_state=111)
df_clf.fit(X_train, y_train) # 모델에 train 데이터를 학습한다.
train_pred =df_clf.predict(X_train)from sklearn.metrics import accuracy_score #사이킷런패키지에서 불러오는 정확도 평가 메트릭스
print('DT train 정확도 : {0:.4f}'.format(accuracy_score(y_train, train_pred))) # accuracy_score(실제값, 예측값 )
# DT train 정확도 : 1.0000
test_pred = df_clf.predict(X_test) # test 데이터로 실제 값을 예측
print('DT train 정확도 : {0:.4f}'.format(accuracy_score(y_train, train_pred))) # accuracy_score(실제값, 예측값 )
print('DT test 정확도 : {0:.4f}'.format(accuracy_score(y_test, test_pred))) # accuracy_score(실제값, 예측값 )
# DT train 정확도 : 1.0000
# DT test 정확도 : 0.9333
traindata에 대해 100%의 정확도를 보인다. 과적합된 모델임을 확인할 수 있다.
DT의 하이퍼파라미터를 조정하여 과적합을 막아본다.
df_clf1 = DecisionTreeClassifier(max_depth =2 ,random_state=111)
df_clf1.fit(X_train, y_train)
train_pred1 =df_clf1.predict(X_train)
print('DT train 정확도 : {0:.4f}'.format(accuracy_score(y_train, train_pred1))) # accuracy_score(실제값, 예측값 )
# DT train 정확도 : 0.9714
교차검증 진행해본다.
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score
from sklearn.model_selection import KFold
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
import numpy as np
import pandas as pdfold_iris = load_iris()
features = fold_iris.data
label = fold_iris.targetfrom sklearn.model_selection import KFold
kfold = KFold(n_splits=5)
cv_acc_train=[]
cv_acc_test=[]
kf_ml = DecisionTreeClassifier(random_state=111,max_depth=3)n_iter = 0
for train_idx, test_idx in kfold.split(features):
X_train, X_test = features[train_idx], features[test_idx]
y_train, y_test = label[train_idx], label[test_idx]
#dt모델 학습하기
kf_ml.fit(X_train, y_train)
#예측
kf_pred_train =kf_ml.predict(X_train)
kf_pred_test =kf_ml.predict(X_test)
# 정확도를 5번 측정할 것
n_iter +=1
acc_train = np.round(accuracy_score(y_train, kf_pred_train),4)
acc_test = np.round(accuracy_score(y_test, kf_pred_test),4)
#교차검증 train, test 정확도 확인
print('\n {} 번 train 교차 검증 정확도 :{}, test의 교차검증 정확도 :{}'.format(n_iter, acc_train, acc_test))
cv_acc_train.append(acc_train)
cv_acc_test.append(acc_test)
print('train 평균 정확도', np.mean(cv_acc_train))
print('test 평균 정확도', np.mean(cv_acc_test))
skf 모델을 활용하여 kfold 문제를 해결해본다.
from sklearn.model_selection import StratifiedKFold
skf_iris = StratifiedKFold(n_splits=5)
cnt_iter = 0
n_iter = 0
skf_cv_acc_train=[]
skf_cv_acc_test=[]
skf_ml = DecisionTreeClassifier(random_state=111,max_depth=3)
#skf 사용한 교차검증
for train_idx, test_idx in skf_iris.split(features,label): #skf split 안에 label
X_train, X_test = features[train_idx], features[test_idx]
y_train, y_test = label[train_idx], label[test_idx]
#skf_dt모델 학습하기
skf_ml.fit(X_train, y_train)
#예측 (skf, split을 통해 진행)
skf_pred_train =skf_ml.predict(X_train)
skf_pred_test =skf_ml.predict(X_test)
# 정확도를 5번 측정할 것
n_iter += 1
acc_train = np.round(accuracy_score(y_train, skf_pred_train),4)
acc_test = np.round(accuracy_score(y_test, skf_pred_test),4)
#교차검증 train, test 정확도 확인
print('\n {} 번 train 교차 검증 정확도 :{}, test의 교차검증 정확도 :{}'.format(n_iter, acc_train, acc_test))
skf_cv_acc_train.append(acc_train)
skf_cv_acc_test.append(acc_test)
print('train 평균 정확도', np.mean(skf_cv_acc_train))
print('test 평균 정확도', np.mean(skf_cv_acc_test))
'B.D.A' 카테고리의 다른 글
| [BDA 데이터 분석 모델링반 (ML 1) 7회차] RFM 분석 (2) | 2024.06.05 |
|---|---|
| [BDA 데이터 분석 모델링반 (ML 1) 6회차] K-means 클러스터링 (0) | 2024.06.04 |
| [BDA 데이터 분석 모델링반 (ML 1) 5회차] KNN 알고리즘 (2) | 2024.06.03 |
| [BDA 데이터 분석 모델링반 (ML 1) 4회차] 임계점 평가지표 (2) | 2024.05.28 |
| [BDA 데이터 분석 모델링반 (ML 1) 3회차] ML 평가지표 (0) | 2024.04.05 |
- Total
- Today
- Yesterday